Mithun Shanbhag
(blog | rss | twitter | linkedin | github)
Quick links
High Availability in Azure: Traffic management
Published on 16 Mar 2019 by Mithun ShanbhagNote: This blog post is part of a series centered around the topic of high availability in Azure:
- The basics
- SLAs and the 9s (coming soon)
- Availability Sets
- Availability Zones
- Storage redundancies
- Load balancing (coming soon)
- Application gateways (coming soon)
- Traffic management (this post)
- App Service, Function Apps
- SQL (coming soon)
- CosmosDB (coming soon)
- Wrapping up (coming soon)
I’ll not be addressing scaling (horizontal or vertical), backups/restores and resiliency/healing in these posts. Each of those topics deserve their own series, perhaps I’ll write about them in the future if time permits.
Azure Traffic Manager

Azure Traffic Manager routes a client’s DNS query to an appropriate service endpoint, selected based on a combination of factors:
- traffic routing methods (user selected)
- health of the endpoints (user configured probing/monitoring rules)
- latency tables (internally maintained map of ip address ranges to regions)
[image attribution: Azure documentation]
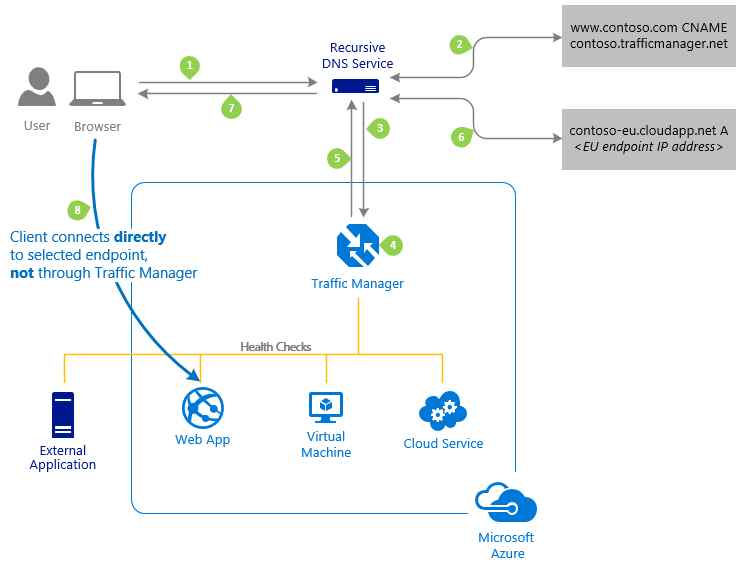
Some scenarios that can be addressed with Azure Traffic Manager are:
- always routing to primary endpoint (with failover to secondary when primary endpoint’s health degrades).
- always routing to endpoint with lowest latency.
- always routing to specific regional endpoint for data sovereignty compliance.
- enabling blue/green deployments with weighted routing.
The Azure Traffic Manager SLA is 99.99%.
Things it is not (or does not do)
- not a gateway or a proxy. Traffic between the client and the service endpoint does not pass through the traffic manager. Once the traffic manager points a client to a service endpoint, the client communicates with the endpoint directly.
- not a layer-7 (application level) solution.
- not a DNS server.
- not a WAF.
- does not offer TLS termination / SSL offload.
- does not offer sticky sessions.
The holy trinity
Azure Traffic Manager is used in conjunction with Azure Application Gateways and Azure Load Balancers. Here is a nice article that explains how the trio complement each other.
[image attribution: Azure documentation]
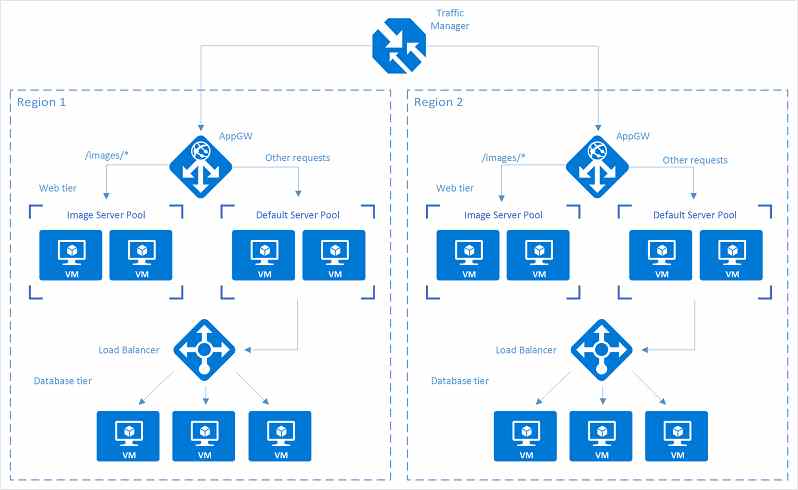
Traffic routing methods
The official docs capture all the traffic routing methods in great detail. However let me provide a quick recap below:
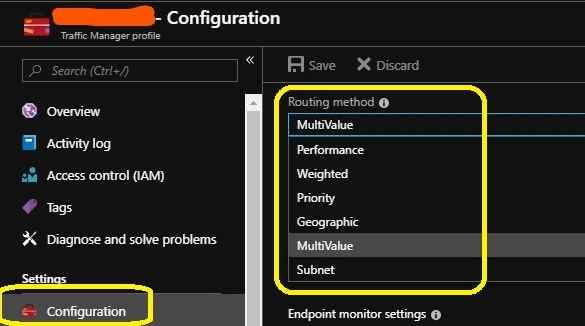
performance routing
Use this when you need to route traffic to a service endpoint with the lowest network latency (as measured from the client IP address).
The Azure Traffic Manager maintains an internal “latency table”, that maps the latencies of IP address ranges to various Azure Regions. Upon an incoming recursive DNS request, it looks up the client’s IP address and detects the IP address range that it falls under. For that address range, it picks up an available service endpoint from an Azure region with the lowest possible latency. If multiple service endpoints are detected within the same Azure region, then the Azure Traffic Manager distributes traffic evenly across them.
priority routing
Use this when you want to route all traffic to a primary endpoint (with a secondary on standby).
All service endpoints are assigned a priority number (value between 1 and 1000 with 1 being highest priority and 1000 being lowest). The primary gets assigned the highest priority (i.e. lowest number) and as a result all traffic gets routed to it. If the primary’s health degrades, all traffic gets routed to the secondary, which has the next highest priority. Manual fail-overs can be initiated by bumping the secondary to higher priority.
weighted routing
Use this when you need to do staggered roll-outs, blue/green deployments.
All service endpoints are assigned a weight (value between 1 and 1000, 1 being lowest weight and 1000 being highest). The traffic manager will attempt to route traffic to available service endpoints based on weighted priorities.
Note: Weighted routing is different from priority routing mentioned above. In priority routing, only the highest priority endpoint is selected and others are ignored (until the highest priority endpoint’s health degrades). With weighted routing, the traffic manager does route traffic to all endpoints, but uses the assigned weights to choose a specific endpoint on each incoming request.
geographic routing
(official docs | tutorial | faqs)
Use this when you need to geo-fence your users to specific regions/geographies (for data sovereignty reasons etc).
Per configuration, client requests will get serviced by endpoints from the specified region (this may or may not be the endpoint with lowest latency). Regional endpoints can be assigned at the following granularities:
- world (highest granularity)
- regional grouping (roughly the same as Azure Geographies)
- country
- state (lowest granularity, only available for USA, Canada and Australia as of the time of writing this blog post).
Lookup always starts from the lowest granularity goes to highest granularity and first match found is returned.
subnet routing
(official docs | tutorial | faqs)
Use this when you need to map specific client IP address ranges to specific service endpoints.
Multivalue routing
(official docs | faqs)
Just mentioning it for completeness sake; I haven’t actually used it ever.
That’s all for today folks! Comments? Suggestions? Thoughts? Would love to hear from you, please leave a comment below or send me a tweet.